
Prompt Injection (phần 2) – Chiến Lược Phòng Thủ và Kỹ Thuật Giảm Thiểu Rủi Ro
Blog . TutorialsContents
Trong phần này, chúng ta sẽ chuyển từ tấn công sang phòng thủ. Mục tiêu là trang bị các kiến thức về phương pháp, chiến lược và công cụ để giảm thiểu rủi ro, từ đó xây dựng các ứng dụng AI an toàn và đáng tin cậy hơn. Triết lý cốt lõi ở đây là phòng thủ theo chiều sâu (defense-in-depth) — một cách tiếp cận đa lớp, nơi mỗi lớp bảo vệ sẽ bù đắp cho những điểm yếu tiềm tàng của các lớp khác. Cần nhấn mạnh rằng, đây là một cuộc chiến liên tục, đòi hỏi sự kiểm thử và cập nhật thường xuyên để đối phó với các biến thể tấn công mới.
1. Các Nguyên Tắc Vàng trong Phòng Thủ
Trước khi đi vào các kỹ thuật cụ thể, chúng ta cần nắm vững ba nguyên tắc nền tảng trong việc thiết kế hệ thống AI an toàn.
-
Nguyên tắc Đặc quyền Tối thiểu (Principle of Least Privilege):
-
Ý tưởng: Chỉ cấp cho LLM những quyền hạn thực sự cần thiết để hoàn thành nhiệm vụ của nó. Đây được xem là nền tảng trong bảo mật AI hiện đại.
-
Ví dụ: Một chatbot AI có chức năng dịch thuật thì không cần quyền truy cập vào cơ sở dữ liệu người dùng hay khả năng gửi email. Việc giới hạn quyền hạn sẽ giảm thiểu thiệt hại nếu kẻ tấn công chiếm được quyền kiểm soát mô hình.
-
-
Không Bao Giờ Tin Tưởng Đầu Vào (Zero Trust Input):
-
Ý tưởng: Luôn coi mọi dữ liệu đầu vào — dù đến từ người dùng hay các nguồn bên ngoài (website, tài liệu) — đều có khả năng chứa mã độc.
-
Ví dụ: Giống như một nhân viên bảo vệ kiểm tra ID của tất cả mọi người vào tòa nhà, kể cả những người trông quen mặt. Mọi dữ liệu đều phải được kiểm tra trước khi được xử lý.
-
-
Yêu cầu Xác thực cho Hành động Nguy hiểm (Human-in-the-Loop – HITL):
-
Ý tưởng: Đối với các hành động có rủi ro cao, LLM chỉ nên đề xuất hành động và phải có một bước xác nhận cuối cùng từ con người trước khi thực thi.
-
Ví dụ: Một trợ lý AI có thể soạn thảo một email xóa tài khoản, nhưng nút “Gửi” cuối cùng phải do người dùng nhấn, sau khi đã đọc và xác nhận nội dung.
-
Hạn chế và Lưu ý: Mặc dù là một lớp kiểm soát quan trọng, HITL không phải là giải pháp vạn năng. Hiệu quả của nó phụ thuộc rất nhiều vào việc thiết kế quy trình giám sát rõ ràng và khả năng của người giám sát trong việc phát hiện các hành vi tinh vi. Kẻ tấn công vẫn có thể cố gắng thao túng người dùng thông qua các kỹ thuật social engineering, và việc triển khai HITL có thể tốn kém về nguồn lực.
-
2. Các Lớp Phòng Thủ Kỹ Thuật
Áp dụng triết lý phòng thủ theo chiều sâu, chúng ta có thể triển khai nhiều lớp kỹ thuật khác nhau.
Lớp 1: Lọc và Vệ sinh Đầu vào (Input Filtering & Sanitization)
Mô tả: Đây là tuyến phòng thủ đầu tiên, nhằm phát hiện và loại bỏ các chỉ thị đáng ngờ trước khi chúng đến được LLM.
Phương pháp:
-
Sử dụng dấu phân cách (Delimiters): Tách biệt rõ ràng giữa chỉ thị hệ thống và dữ liệu không đáng tin cậy.
-
Phát hiện từ khóa tấn công: Quét đầu vào để tìm các cụm từ tấn công phổ biến.
-
Sử dụng LLM làm “người gác cổng” (Guardrail): Dùng một mô hình AI khác để kiểm tra và phân loại mức độ an toàn của đầu vào.
Hạn chế: Các kỹ thuật che giấu (obfuscation) hoặc tấn công đa ngôn ngữ vẫn là thách thức lớn, đòi hỏi các bộ lọc phải liên tục được cập nhật.
Lớp 2: Kỹ thuật Thiết kế Prompt An Toàn (Secure Prompt Engineering)
Mô tả: Cách xây dựng các prompt hệ thống (system prompt) có khả năng chống lại việc bị ghi đè tốt hơn.
Phương pháp:
-
Đặt chỉ thị ở cuối: Một số nghiên cứu cho thấy LLM có xu hướng tuân theo các chỉ thị ở cuối prompt hơn.
-
Hướng dẫn bằng ví dụ (Few-shot Prompting): “Dạy” mô hình cách từ chối bằng cách đưa ra các ví dụ về những yêu cầu không an toàn.
Hạn chế: Hiệu quả của các kỹ thuật này có thể thay đổi tùy thuộc vào từng mô hình LLM cụ thể. Do đó, việc kiểm thử thực tế trên mô hình của bạn là rất quan trọng để xác định phương pháp tối ưu.
Lớp 3: Giám sát và Lọc Đầu ra (Output Monitoring & Filtering)
Mô tả: Kiểm tra kết quả do LLM tạo ra trước khi nó được hiển thị cho người dùng hoặc chuyển tiếp đến một hệ thống khác.
Phương pháp:
-
Quét dữ liệu nhạy cảm: Tìm kiếm và che giấu (mask) các thông tin nhạy cảm trong đầu ra.
-
Phát hiện lệnh gọi hàm: Kiểm tra xem đầu ra có chứa các lệnh gọi công cụ hoặc API không mong muốn hay không.
-
Sử dụng “Từ mồi” (Canary Words): Chèn một chuỗi bí mật, ngẫu nhiên vào dữ liệu. Nếu chuỗi này xuất hiện ở đầu ra, đó là dấu hiệu rõ ràng của việc rò rỉ dữ liệu.
Hạn chế: Các bộ lọc đầu ra cần được cập nhật liên tục để đối phó với các kỹ thuật tấn công và rò rỉ dữ liệu mới. Hiệu quả của Canary Words có thể bị hạn chế nếu kẻ tấn công phát hiện và loại bỏ chúng.
Lớp 4: Các Biện pháp Cấp Hệ thống (System-Level Controls)
Mô tả: Các biện pháp bảo vệ được tích hợp vào kiến trúc và môi trường hoạt động của ứng dụng.
Phương pháp:
-
Sandboxing: Nếu LLM cần sử dụng các công cụ (như trình thông dịch code), hãy cô lập môi trường hoạt động của chúng trong một “hộp cát” (sandbox) với quyền hạn cực kỳ hạn chế.
-
API Gateway: Tạo các API trung gian với quyền hạn được định nghĩa chặt chẽ.
-
Kiểm soát Truy cập Động (Dynamic Access Control): Thay vì cấp quyền tĩnh, hệ thống có thể cấp quyền truy cập vào dữ liệu hoặc công cụ một cách linh động dựa trên ngữ cảnh của yêu cầu, giúp thu hẹp bề mặt tấn công trong từng phiên làm việc.
-
Giám sát và Ghi nhật ký (Monitoring and Logging): Theo dõi chặt chẽ tất cả các prompt đầu vào và đầu ra để phát hiện các hoạt động đáng ngờ và phản ứng kịp thời.
3. Công Cụ và Triển Khai Thực Tế
3.1. Các Công cụ Mã nguồn Mở
Cộng đồng mã nguồn mở cung cấp nhiều công cụ để hỗ trợ việc phòng thủ và kiểm thử:
-
Rebuff: Một thư viện Python để phát hiện tấn công bằng nhiều lớp phòng thủ, bao gồm cả “canary word”.
-
promptmap: Một công cụ giúp tự động kiểm tra và đánh giá khả năng bị tấn công của ứng dụng.
-
LLM Guard: Một framework toàn diện để định nghĩa các chính sách lọc cho cả đầu vào và đầu ra.
3.2. Cách Tiếp cận của các Công ty Lớn
-
Google: Sử dụng cách tiếp cận “phòng thủ theo chiều sâu”, bao gồm các bộ phân loại để phát hiện nội dung độc hại, gia cố prompt, và yêu cầu xác nhận của người dùng cho các hành động nguy hiểm.
-
Microsoft: Áp dụng triết lý “zero-trust”, khuyến nghị các biện pháp như giới hạn quyền truy cập, mã hóa đầu vào, và triển khai các bước phê duyệt thủ công.
4. Các Hướng Nghiên Cứu và Giải Pháp Tiên Tiến
Cộng đồng nghiên cứu đang khám phá các giải pháp tiên tiến hơn:
-
Huấn luyện Đối kháng (Adversarial Training): “Dạy” LLM cách chống lại tấn công bằng cách huấn luyện chúng trên các tập dữ liệu chứa các ví dụ về prompt injection. Đây là một hướng nghiên cứu chủ đạo.
-
Kiến trúc Đa Mô hình (Dual-LLM Approaches): Sử dụng một LLM làm “giám sát viên” để kiểm tra đầu vào và đầu ra của một LLM khác.
-
Kỹ thuật Đóng dấu (Watermarking): Nhúng các tín hiệu ẩn vào đầu ra của mô hình để có thể truy vết nguồn gốc của thông tin bị rò rỉ.
5. Kết Luận và Lời Khuyên Thực Tiễn
Prompt Injection là một thách thức phức tạp và dai dẳng. Không có giải pháp nào là hoàn hảo, và cuộc chiến chống lại nó là một “cuộc chạy đua vũ trang” không ngừng nghỉ. Thay vì tìm kiếm một giải pháp duy nhất, việc áp dụng một chiến lược phòng thủ theo chiều sâu, kết hợp nhiều lớp bảo vệ và liên tục cải tiến, là cách tiếp cận thực tế và hiệu quả nhất.
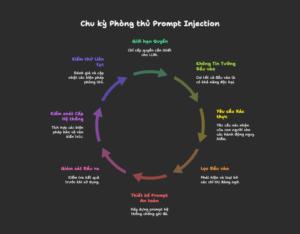
Hãy sử dụng danh sách kiểm tra (checklist) sau đây khi xây dựng hoặc đánh giá ứng dụng AI của bạn:
-
Giới hạn quyền: LLM có đang hoạt động với đặc quyền tối thiểu không?
-
Xác thực hành động: Các hành động nguy hiểm có yêu cầu sự xác nhận của người dùng không? Quy trình HITL có được định nghĩa rõ ràng không?
-
Lọc đầu vào: Bạn có đang kiểm tra và làm sạch dữ liệu đầu vào không?
-
Thiết kế Prompt: Prompt hệ thống của bạn có được thiết kế để chống lại việc bị ghi đè không?
-
Lọc đầu ra: Bạn có đang kiểm tra đầu ra của LLM trước khi sử dụng nó không?
-
Sandboxing: Nếu LLM sử dụng công cụ, chúng có được cô lập trong môi trường an toàn không?
-
Giám sát: Bạn có đang ghi lại nhật ký và giám sát các hoạt động bất thường không?
-
Kiểm thử liên tục: Bạn có thường xuyên thực hiện các bài kiểm tra (red-teaming) để đánh giá hiệu quả của các biện pháp phòng thủ trước các kỹ thuật tấn công mới không?
Cảm ơn bạn đã đọc bài viết này!

 - Phân Tích về Các Kỹ Thuật Tấn Công")

 và Kiến Trúc Nhận Thức (Cognitive Architecture Prompt) trong AI")



: Từ Cơ Bản Đến Chuyên Gia")

 khi tương tác với Gen AI và cách khắc phục nó qua Prompt")