
Context Rot – Vì sao cho mô hình thêm thông tin đôi khi làm kết quả tệ đi?
BlogContents
Chào mừng bạn đến với Fx Studio. Bài blog này sẽ đi tìm hiểu một khái niệm rất thú vị, đó là Context Rot.
Có một giả định ngầm trong cách phần lớn chúng ta dùng mô hình ngôn ngữ. Khi câu trả lời chưa đủ tốt, phản xạ đầu tiên là cung cấp thêm. Thêm tài liệu, thêm ví dụ, thêm lịch sử hội thoại, thêm vài đoạn nền cho chắc. Nằm dưới phản xạ đó là một niềm tin: mô hình xử lý token thứ mười nghìn cũng cẩn thận như token thứ một trăm.
Niềm tin này nghe hợp lý. Nó cũng sai.
Hiện tượng mà cộng đồng nghiên cứu đang gọi bằng cái tên Context rot cho thấy điều ngược lại. Khi số token trong context tăng, khả năng truy hồi và suy luận chính xác của mô hình giảm, và sự suy giảm đó xuất hiện trước cả khi context chạm giới hạn cứng của cửa sổ. Luận điểm của bài này có thể gói trong một câu. Bổ sung dữ kiện vào context không đồng nghĩa với cải thiện kết quả; quá một ngưỡng, mỗi token thêm vào lại làm loãng sự chú ý mà mô hình dành cho phần thật sự quan trọng.
Hiện tượng và bằng chứng cho nó
Cụm từ context rot được hệ thống hóa trong một báo cáo năm 2025 của Chroma. Thiết kế thực nghiệm của họ đáng chú ý ở một điểm phương pháp luận. Khó khăn thường gặp khi đánh giá năng lực long-context là độ phức tạp của bài toán có xu hướng tăng theo độ dài đầu vào, khiến ta không tách được sự sụt giảm là do input dài hơn hay do bài toán vốn khó hơn. Chroma xử lý điều này bằng cách giữ độ phức tạp của tác vụ cố định và chỉ thay đổi độ dài đầu vào. Nhờ vậy, mọi thay đổi trong kết quả có thể quy về một biến duy nhất là độ dài.
Context rot (có thể tạm dịch là suy giảm ngữ cảnh) là hiện tượng hiệu suất và độ chính xác của các mô hình Trí tuệ Nhân tạo (AI) bị giảm đi khi bạn cung cấp cho nó một lượng ngữ cảnh đầu vào quá lớn.
Kết quả nhất quán một cách khó chịu. Trên mười tám mô hình hàng đầu được đánh giá, trong đó có GPT-4.1, Claude 4, Gemini 2.5 và Qwen3, không mô hình nào giữ được hiệu suất đồng đều khi đầu vào dài ra. Không phải một số. Không phải phần lớn. Tất cả đều suy giảm, và suy giảm theo từng mức tăng độ dài, kể cả trên những tác vụ đơn giản như truy hồi hay sao chép văn bản.
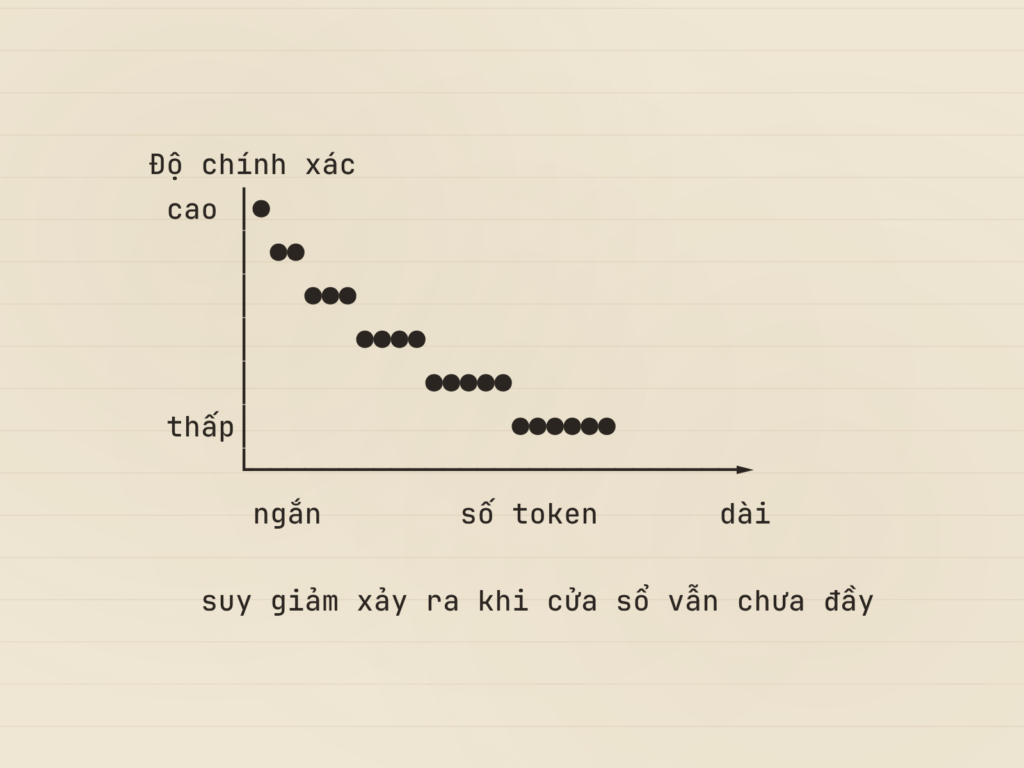
Điều khiến hiện tượng này dễ bị bỏ qua là các benchmark phổ biến vẽ nên một bức tranh khác. Bài test được dùng nhiều nhất, Needle in a Haystack, yêu cầu mô hình tìm một câu được cài vào giữa một khối văn bản dài. Các mô hình hiện đại gần như đạt điểm tuyệt đối ở bài này, nên người ta dễ kết luận chúng đọc đều mọi token. Vấn đề là công việc thật hiếm khi giống tìm kim. Trong thực tế, mô hình phải suy luận giữa hàng trăm mẩu thông tin nửa liên quan, phân biệt cái trọng yếu với cái chỉ trông giống trọng yếu. Đó là điều kiện mà điểm số gần tuyệt đối trên Needle in a Haystack không phản ánh.
Cơ chế: vì sao chú ý lại loãng đi
Để hiểu vì sao một mô hình lại tệ đi khi được cho nhiều hơn, cần nhìn vào lớp cơ chế bên dưới chứ không dừng ở việc mô tả hiện tượng. Có ít nhất ba lực cùng tác động.
Lực thứ nhất nằm ngay trong kiến trúc transformer. Cơ chế attention vận hành bằng cách cho mỗi token tham chiếu tới mọi token khác trong context để quyết định nên dựa vào đâu. Số quan hệ cần tính tăng theo bình phương độ dài. Một context một trăm nghìn token kéo theo khoảng mười tỷ cặp quan hệ, và toàn bộ trọng số attention vẫn phải được phân bổ trên cùng một ngân sách. Hệ quả trực tiếp là khi tổng số token tăng, lượng chú ý trung bình dành cho mỗi token giảm. Thông tin quan trọng không biến mất khỏi context, nhưng phần chú ý nó nhận được bị san mỏng giữa một đám đông ngày càng lớn.
Lực thứ hai là hiệu ứng vị trí, được nghiên cứu của Stanford mô tả dưới tên lost in the middle. Mô hình điều kiện hóa mạnh nhất trên phần đầu và phần cuối của context, còn phần giữa thì xử lý kém hơn rõ rệt. Khi thông tin liên quan bị đặt vào chính giữa một context dài, độ chính xác có thể tụt hơn ba mươi phần trăm so với khi nó nằm ở rìa. Điều này biến vị trí của một mẩu thông tin thành biến thiết kế, không phải chi tiết phụ.
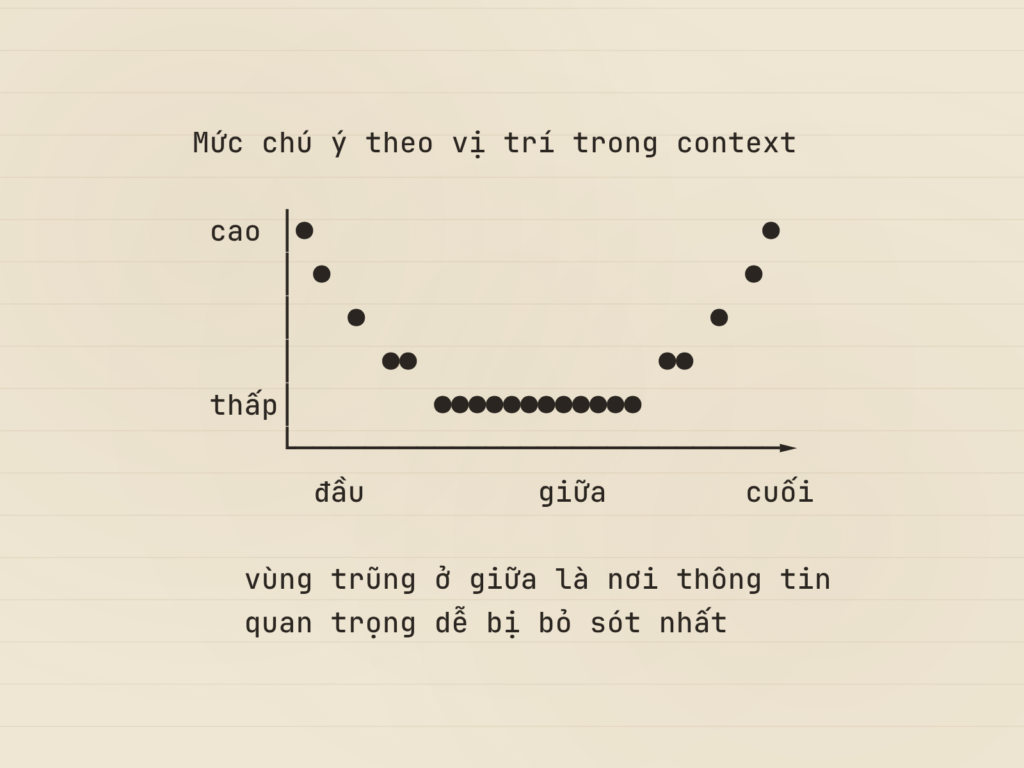
Lực thứ ba là nhiễu ngụy trang. Một đoạn văn bản gần giống thứ ta cần tìm còn nguy hiểm hơn một đoạn hoàn toàn vô can. Vì mô hình có xu hướng dùng những gì được cấp, một mẩu trông liên quan nhưng thực ra không liên quan sẽ kéo nó bám vào sai chỗ. Gần đúng gây hại hơn sai hẳn, bởi sai hẳn dễ bị loại còn gần đúng thì len được vào suy luận.
Ba lực này cộng hưởng. Càng nhiều token, attention càng loãng, phần giữa càng dày, và xác suất có một đoạn gần giống gây nhiễu càng cao.
Phân biệt với tràn cửa sổ
Một sai lầm khái niệm phổ biến là đánh đồng context rot với tràn cửa sổ. Hai thứ này khác nhau về bản chất.
- Tràn cửa sổ là một thất bại nhị phân: vượt giới hạn token, phần thừa bị cắt hoặc bị từ chối, và ta biết ngay điều gì xảy ra.
- Context rot là sự xuống cấp liên tục diễn ra trong lúc cửa sổ vẫn còn trống.
Một nghiên cứu của Databricks ghi nhận độ chính xác bắt đầu rạn quanh mốc ba mươi hai nghìn token, sớm hơn rất nhiều so với các cửa sổ triệu token đang được quảng bá. Tương tự, bộ đánh giá LongMemEval đo được khoảng cách ba mươi tới sáu mươi phần trăm về hiệu suất giữa một prompt khoảng ba trăm token và một prompt khoảng một trăm mười ba nghìn token, trên cùng một tác vụ.
Hàm ý của sự phân biệt này khá nặng. Dung lượng cửa sổ là một thông số hữu ích để tiếp thị, nhưng nó không phải thước đo năng lực sử dụng thực tế. Thứ quyết định chất lượng đầu ra không phải mô hình chứa được bao nhiêu token, mà tỉ lệ giữa tín hiệu và nhiễu trong số token được đưa vào. Nói cách khác, hai prompt cùng nằm gọn trong cửa sổ vẫn có thể cho kết quả chênh nhau rất xa, tùy phần bị pha loãng nhiều hay ít.
Từ cơ chế tới nguyên tắc dùng được
Nếu cơ chế là vậy, các nguyên tắc thực hành rút ra khá tự nhiên. Chúng không phải mẹo rời rạc mà là hệ quả trực tiếp của ba lực ở trên.
Nguyên tắc đầu tiên, và bao trùm, đến từ tài liệu của Anthropic về context engineering: tìm tập token tín hiệu cao nhỏ nhất đủ để mô hình ra đúng kết quả. Cách diễn đạt này đảo ngược thói quen mặc định. Mục tiêu không phải nạp đủ thông tin để chắc chắn, mà cắt tới khi không còn gì để cắt mà vẫn đúng. Một prompt tốt được định nghĩa bởi phần đã loại bỏ nhiều hơn phần đã thêm vào.
Nguyên tắc thứ hai bám thẳng vào hiệu ứng lost in the middle. Hãy đặt yêu cầu cốt lõi và thông tin trọng yếu ở đầu hoặc cuối context, đừng chôn chúng vào giữa một khối log dài. Phần giữa là vùng mô hình lơ đãng nhất, và để thông tin quan trọng nằm đó là tự bỏ đi một phần độ chính xác mà không cần thiết.
Nguyên tắc thứ ba là lấy context đúng lúc thay vì nạp sẵn. Thay vì dồn toàn bộ tài liệu vào prompt ngay từ câu đầu, để hệ thống truy xuất phần cần khi tới lúc cần. Cách tiếp cận just-in-time mà Anthropic mô tả giữ cho mỗi lượt gọi chỉ mang theo phần context có liên quan, qua đó giảm cả ba lực gây loãng cùng lúc.
Nguyên tắc thứ tư là cắt distractor, không chỉ cắt rác. Vì nhiễu gần giống tín hiệu mới là thứ gây hại nhiều nhất, việc rà soát phải nhắm cả vào những đoạn trông liên quan nhưng không đóng góp cho câu trả lời. Một tài liệu thừa không phải lựa chọn dự phòng vô hại, nó là một nguồn nhiễu.
Nguyên tắc thứ năm dành cho ai vận hành agent chạy dài. Khi kết quả tool và phần suy luận tích lũy qua nhiều bước, chúng sẽ dần lấp đầy context bằng thứ không còn giá trị. Các kỹ thuật tóm tắt và cắt tỉa theo luật, mà Anthropic gọi chung là compaction, giữ cho context không tự đầu độc theo thời gian. Một agent không dọn context đang trả tiền để ghi nhớ những thứ đáng quên.
Nguyên tắc cuối cùng là đo, đừng tin cảm giác. Mọi thay đổi về cách dựng context nên được kiểm chứng bằng một tập eval cố định, đánh giá ở chính độ dài mà hệ thống chạy trong thực tế. Khoảng cách ba mươi tới sáu mươi phần trăm mà LongMemEval ghi nhận cho thấy hiệu suất ở độ dài thật khác xa hiệu suất ở prompt ngắn dùng để thử. Không có eval, thứ ta cải thiện thường là cảm giác về context chứ không phải bản thân context.
Một cuộc đua đặt sai chỗ
Phần lớn cuộc cạnh tranh hiện nay diễn ra quanh dung lượng cửa sổ. Một triệu token, rồi nhiều triệu token, được trưng ra như bằng chứng năng lực. Bằng chứng từ context rot gợi ý cuộc đua này đang đặt ở sai tầng. Khả năng chứa nhiều token không tự động chuyển thành khả năng dùng tốt số token đó, và quá một ngưỡng, chứa thêm còn làm hại.
Điều này định hình lại đâu là kỹ năng đáng đầu tư. Năng lực của mô hình rồi sẽ tiến tới chỗ ai cũng tiếp cận được những cửa sổ rất dài. Thứ khó sao chép hơn là kỷ luật quyết định cái gì được vào context và cái gì bị giữ ngoài. Quay lại đúng luận điểm ban đầu: chất lượng một câu trả lời được quyết định nhiều bởi phần ta loại bỏ, chứ không chỉ bởi phần ta đưa thêm vào.
Tạm kết
Context rot không phải một lỗi của riêng mô hình nào, mà là một thuộc tính của cách kiến trúc hiện tại phân bổ sự chú ý. Khi đã nhìn rõ ba lực bên dưới, attention loãng theo bình phương độ dài, hiệu ứng vị trí ở phần giữa, và nhiễu gần giống tín hiệu, thì phần lớn các nguyên tắc thực hành không còn là mẹo rời rạc mà trở thành hệ quả tự nhiên. Cắt cho gọn, đặt thông tin đúng chỗ, lấy đúng lúc, và đo ở độ dài thật.
Bài này chưa khép lại được mọi nhánh. Câu hỏi mở còn đó là khi nào nên cô lập context sang nhiều agent thay vì dọn một context duy nhất, và làm thế nào để dựng một bộ eval đủ rẻ mà vẫn bắt được sự xuống cấp ở độ dài lớn. Tôi để dành cho các bài sau. Điều cần giữ lại từ đây chỉ gọn một ý: với mô hình ngôn ngữ, thêm thông tin và thêm hiểu biết là hai chuyện khác nhau, và lẫn lộn hai cái là nguồn gốc của phần lớn các prompt phình to mà kết quả lại đi xuống.
Tham khảo
- Chroma Research, Context Rot: How Increasing Input Tokens Impacts LLM Performance (2025): https://research.trychroma.com/context-rot
- Nelson F. Liu và cộng sự, Lost in the Middle: How Language Models Use Long Contexts (Stanford, TACL 2024): https://arxiv.org/abs/2307.03172
- Di Wu và cộng sự, LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory (2024): https://arxiv.org/abs/2410.10813
- Anthropic, Effective context engineering for AI agents: https://www.anthropic.com/engineering/effective-context-engineering-for-ai-agents
- Drew Breunig, How Long Contexts Fail (gồm cả phần tổng hợp ghi nhận của Databricks): https://www.dbreunig.com/2025/06/22/how-contexts-fail-and-how-to-fix-them.html
Cảm ơn bạn đã đọc bài viết này!
Related Posts:
: Khung WSCI Áp Dụng Cho AntiGravity")
 trong Prompt Engineering")
 và Kiến Trúc Nhận Thức (Cognitive Architecture Prompt) trong AI")

Leave a Reply
Donate – Buy me a coffee!

: Nâng Cao Độ Tin Cậy Của Mô Hình Ngôn Ngữ Lớn")


