
5 Thuật Ngữ AI Nền Tảng – Hiểu Đúng Để Dùng AI Thông Minh Hơn
BlogContents
Xin chào, mình là Khoa. Bài viết hôm nay trên Fx Studio sẽ nói về một thứ tưởng cũ nhưng ít người tìm hiểu kỹ: những thuật ngữ AI nền tảng mà ai dùng ChatGPT, Claude hay Gemini cũng vô tình đi ngang qua.

5 thuật ngữ AI nền tảng mọi developer nên biết – Fx Studio
Đôi lời tản mạn
Có một câu hỏi mà mình thấy được hỏi đi hỏi lại trên các group developer Việt Nam dạo gần đây: “Sao hôm trước AI trả lời ngon vậy mà giờ kém hẳn?”, “Tại sao Claude/ChatGPT lúc thì hiểu ý mình, lúc thì… không?”, “AI vừa update gì đó hay sao mà nó khác trước?”
Đọc nhiều câu hỏi như vậy, mình nhận ra một điều khá thú vị. Phần lớn không phải vì model “đổi tính”. Cũng không phải vì các nhà cung cấp bí mật hạ chất lượng (một thuyết âm mưu khá phổ biến). Mà vì người dùng — kể cả developer — đang dùng AI như một hộp đen, không biết rõ những gì đang diễn ra bên trong. Đến khi output khác đi, cả lý do và cách xử lý đều mơ hồ.
Mình tin là nếu bạn nắm được một vài thuật ngữ AI cơ bản nhất, phần lớn các “hiện tượng lạ” của AI sẽ tự sáng tỏ. Không phải để bạn trở thành ML engineer, mà để bạn dùng công cụ này tỉnh táo hơn — biết khi nào tin, khi nào điều chỉnh, khi nào cần đổi cách tiếp cận.
Trong bài này, mình muốn cùng bạn đi qua 5 khái niệm cốt lõi: Token, Context Window, Temperature, Hallucination, và RAG. Đọc xong, bạn sẽ thấy cách AI hoạt động rõ ràng hơn, và quan trọng hơn — bạn sẽ kiểm soát được nó nhiều hơn. Bắt đầu thôi!
Token — Đơn vị “tiền tệ” thật sự của LLM
Khởi động nhẹ nhàng nhé. Khi bạn gõ một câu vào ChatGPT, bạn nghĩ AI đọc nó như chúng ta đọc — từng chữ, từng từ. Thực tế thì không hề. Trước khi xử lý, AI cho câu của bạn đi qua một thành phần gọi là tokenizer, chuyên cắt văn bản ra thành những mẩu nhỏ. Mỗi mẩu được gọi là một token — thuật ngữ AI đầu tiên bạn cần làm rõ trước khi bước vào những khái niệm phía sau.
Vậy token có hình thù như thế nào? Đôi khi token là cả một từ, đôi khi chỉ là một phần của từ, và cũng có lúc chỉ vỏn vẹn một dấu câu. Tất cả tùy thuộc vào tokenizer và độ phổ biến của từ trong training data.
Một ví dụ cụ thể
Lấy một ví dụ rất quen thuộc với developer: chuỗi console.log("Xin chào"). Nếu bạn paste vào tokenizer chính thức của OpenAI, kết quả là 7 token: console, ., log, (", Xin, chào, "). Bảy token cho một dòng code mà mắt người chỉ thấy có vài “thứ”. (Tokenizer này hiện dùng encoding o200k_base cho các model hiện đại như GPT-4o, GPT-5, o-series.)
Vì sao bạn nên quan tâm đến token? Hai lý do:
- Token là đơn vị tính tiền của AI API. Khi bạn gọi API của OpenAI, Anthropic, Google — họ tính phí theo số token bạn gửi vào và số token AI trả ra. Không phải theo từ, không phải theo câu, mà theo token.
- Token là đơn vị giới hạn. Mỗi model có giới hạn về số token có thể xử lý cùng lúc (sẽ nói kỹ ở phần Context Window phía dưới).

Minh họa cách tokenizer cắt token – một trong những thuật ngữ AI nền tảng
Vì sao tiếng Việt “đắt” token hơn tiếng Anh?
Tiếng Việt tốn token hơn tiếng Anh. Vì các tokenizer phổ biến — BPE (Byte Pair Encoding) và SentencePiece — được train chủ yếu trên dữ liệu tiếng Anh. Nói nôm na: chúng “quen” với tiếng Anh hơn nên cắt tiếng Anh thành ít mảnh hơn.
Cùng một ý — tiếng Việt Xin chào, hôm nay thời tiết đẹp tốn 9 token, tiếng Anh Hello, the weather is nice today tốn 7 token, chênh khoảng 30%. Nghe không nhiều, nhưng đó mới chỉ là một câu ngắn. Với đoạn văn dài hoặc nội dung phức tạp, chênh lệch có thể tăng lên 1.5-2 lần, vì các từ tiếng Việt có dấu thường bị tokenizer cắt nhỏ thành nhiều mảnh. Tin tốt là encoding o200k_base mới đã cải thiện đáng kể so với cl100k_base cũ. Dù vậy, tiếng Việt vẫn “đắt” hơn tiếng Anh.
Điều này có ý nghĩa thực tế với developer:
- Khi gọi API trả phí, làm app cho user Việt → chi phí mỗi request cao hơn bạn ước tính.
- Khi context window có giới hạn → tài liệu tiếng Việt “ăn” context nhanh hơn tài liệu tiếng Anh cùng độ dài.
- Khi đo độ dài để truncate → đếm ký tự thường không đủ, phải đếm token.
Một cách kiểm tra nhanh: vào tokenizer chính thức của OpenAI, paste văn bản vào và xem nó được cắt ra sao. Bạn sẽ thấy nhiều điều khá bất ngờ.
Context Window — Bộ nhớ làm việc của LLM
Bạn đã bao giờ chat với ChatGPT một lúc lâu rồi bỗng nhận ra nó “quên” mất điều bạn nói lúc đầu cuộc trò chuyện chưa? Đó không phải lỗi. Đó là vì cuộc trò chuyện đã vượt quá context window của model.
Nếu token là đơn vị, thì context window là toàn bộ số token mà model có thể “nhìn thấy” cùng một lúc — chính là bộ nhớ làm việc của nó.
Mình thích ví von context window như một tấm bảng trắng đặt trước mặt người đang làm việc. Mọi thứ ghi trên bảng đều ở trong tầm mắt và có thể dùng đến. Khi bảng đã chật, muốn ghi thêm thì phải xóa bớt phần cũ. Còn những gì đã bị xóa — coi như biến mất, không truy lại được. “Tấm bảng” này thường chứa:
| Thành phần | Vai trò |
|---|---|
| System prompt | Định nghĩa nhân vật, ràng buộc (ví dụ: “Bạn là trợ lý lập trình”) |
| Lịch sử hội thoại | Các turn (lượt trao đổi) trước đó |
| Câu hỏi hiện tại | Input bạn vừa gửi |
| Tài liệu kèm theo | PDF, code, hình ảnh đính kèm |
| Output đang sinh | Phần model đang tự “đọc lại” khi viết câu trả lời |
Tổng số token của tất cả thành phần trên không được vượt quá giới hạn của model. Model nhỏ chỉ có khoảng 8K token (khoảng 6,000 từ tiếng Anh). Model lớn như Gemini 3.1 Pro hay Claude Opus 4.6 đẩy lên 1M, 10M token — đủ để “nuốt” cả một cuốn sách trong một lần gọi.
Lớn không có nghĩa là tốt. Một context 1 triệu token nhưng nhồi đầy rác đôi khi còn kém hiệu quả hơn 32K token được sắp xếp gọn gàng và đúng trọng tâm.
Hiểu lầm phổ biến về “AI tự quên”
Đây là chỗ mình muốn đính chính một hiểu lầm phổ biến: nhiều bạn nghĩ khi context đầy, model sẽ “tự động quên token cũ” như RAM máy tính. Sự thật không phải vậy. Khi bạn gửi request qua API vượt quá context limit, OpenAI hay Anthropic sẽ trả về lỗi — chứ không tự cắt giúp bạn. Việc “quên” mà bạn cảm nhận trong ChatGPT hay Claude.ai thực ra đến từ logic xử lý của ứng dụng, không phải hành vi mặc định của model. Có thể là truncation — cắt bớt phần đầu hội thoại, có thể là summarization — tóm tắt phần cũ thành dạng ngắn hơn.
Hiện tượng “lost in the middle”
Còn một vấn đề tinh tế hơn nhiều người không biết: lost in the middle. Các nghiên cứu cho thấy model có xu hướng chú ý mạnh vào phần đầu và phần cuối context, còn thông tin nằm giữa thì… dễ bị bỏ sót. Bạn có thể đọc thêm về vấn đề này trong bài Context Window Management for LLM Apps — phân tích khá sâu về lost in the middle và context rot.
Nếu bạn muốn đi sâu hơn vào cách thiết kế context có hệ thống, trên Fx Studio có bài Hướng Dẫn Kỹ Thuật Ngữ Cảnh WSCI & Cấu Trúc Workspace — giới thiệu một framework cụ thể (Write-Select-Compress-Isolate) khá đáng đọc nếu bạn đang build app với LLM.
Temperature — Núm vặn “nghiêm túc vs phá cách”
Bạn có bao giờ để ý: cùng một câu hỏi, có lúc AI trả lời rất “an toàn” và đúng mực, có lúc nó lại “phiêu” theo cách hơi bất ngờ? Phần lớn sự khác biệt đó đến từ một tham số tên là temperature — núm vặn quyết định AI nên “nghiêm túc” hay “phá cách”.
Đây là khái niệm mà mình thấy bị bỏ quên nhiều nhất. Người mới không biết nó tồn tại. Người dùng trung cấp nghĩ nó chỉ có giá trị từ 0 đến 1. Còn người dùng chuyên thì… cũng hiếm khi đụng tới.
Để hiểu temperature, mình cần đi sâu thêm một chút vào cách model thực sự sinh ra token.
Mỗi khi cần chọn token tiếp theo, model không “biết” token nào đúng. Nó tính ra một bảng xác suất trên toàn bộ từ vựng (có thể 50,000-100,000 token). Token nào “hợp lý” hơn thì có xác suất cao hơn. Sau đó, model dùng một thuật toán sampling để chọn ra một token cụ thể.
Temperature chính là tham số điều chỉnh quá trình sampling này:
- Temperature thấp (0.0 – 0.3): Chênh lệch xác suất bị làm nổi rõ hơn — token có xác suất cao nhất gần như luôn được chọn. Output ổn định, có thể tái tạo, ít bất ngờ. Lý tưởng cho coding, dịch thuật, trích xuất dữ liệu.
- Temperature trung bình (0.4 – 0.8): Cân bằng giữa ổn định và đa dạng. Mặc định của phần lớn ứng dụng.
- Temperature cao (0.9 – 1.5+): Chênh lệch xác suất bị san phẳng — các token “hiếm” cũng có cơ hội được chọn. Output sáng tạo hơn, đa dạng hơn, nhưng cũng dễ lạc đề. Phù hợp brainstorm, viết sáng tạo.
Ví dụ thực tế: slogan quán cà phê
Lấy một use case quen thuộc: bạn yêu cầu AI viết một câu slogan cho quán cà phê.
- Temperature 0.2: “Cà phê Đậm Đà — Hương Vị Khó Quên” (an toàn, dễ đoán, na ná hàng nghìn slogan khác).
- Temperature 1.2: “Mỗi giọt là một câu chuyện đang chờ kể” hoặc thậm chí “Cà phê — nơi thời gian quên mất đường về” (sáng tạo, gây ấn tượng, nhưng đôi khi cũng… hơi lạ tai).
Quy tắc đơn giản: cần đáp án đúng → temperature thấp. Cần đáp án hay → temperature cao.
Top-p, top-k và những tham số sampling khác
Một điểm thú vị mà nhiều người bỏ qua: ngoài temperature còn có top-p (nucleus sampling) và top-k. Cả ba thường được dùng cùng nhau. Trong thực tế triển khai, top-p được tin dùng hơn vì nó “thông minh” hơn — chỉ chọn từ một tập token có tổng xác suất tích lũy đạt ngưỡng p. Nhưng đó là câu chuyện dành cho một bài khác.
Một lưu ý quan trọng: trong các app như ChatGPT, Claude.ai, bạn không chỉnh được temperature trực tiếp. Nó đã được đặt sẵn ở mức cân bằng. Chỉ khi bạn gọi qua API hoặc dùng các tool dev như Anthropic Console, OpenAI Playground — bạn mới tinh chỉnh được giá trị temperature.
Hallucination — Khi AI “thuyết phục” bạn về điều không có thật
Hallucination — hay “ảo giác” theo cách dịch phổ biến trong tiếng Việt — có lẽ là thuật ngữ AI gây bối rối nhất. Đây là hiện tượng khi model đưa ra thông tin sai nhưng vẫn nói với giọng điệu tự tin hệt như khi nói đúng. Không ngập ngừng. Không kèm theo “có lẽ” hay “mình không chắc”. Chỉ một dòng trôi chảy, mạch lạc.
Để bạn dễ hình dung, mình kể một trải nghiệm đáng nhớ. Mình hỏi ChatGPT về một thư viện iOS để xử lý animation phức tạp, và nó liệt kê 5 thư viện — tên, link GitHub, số star, ngày commit cuối. Mọi thứ nhìn khá chỉn chu. Mình copy tên thư viện thứ 3 đi search, kết quả: không tồn tại. Không hề có thư viện nào tên như thế. Nhưng đoạn mô tả AI đưa ra nghe thuyết phục đến lạ.
Vì sao hallucination xảy ra?
Câu trả lời nằm ở bản chất của LLM:
LLM không phải database. Nó không tra cứu — nó dự đoán. Mỗi câu trả lời được tạo ra bằng cách đoán token tiếp theo nào có khả năng xuất hiện cao nhất, dựa trên pattern đã học từ hàng tỷ văn bản trong quá trình training. Không có cơ chế tự kiểm tra với “sự thật”.
Khi model “không biết” một thông tin cụ thể, nó không có lựa chọn “im lặng”. Nó vẫn phải sinh ra một chuỗi token nào đó. Và token nào nghe có vẻ hợp ngữ cảnh nhất sẽ được chọn — bất kể đúng hay sai. Đây là lý do hallucination luôn tồn tại ở các LLM hiện tại: nó thuộc về bản chất của cách model hoạt động, không phải một lỗi kỹ thuật có thể fix.
Nguyên tắc thực hành: kiểm chứng mọi thứ
Nếu bạn muốn đào sâu hơn về cơ chế và cách giảm thiểu hallucination thông qua prompt, trên Fx Studio có bài Vấn đề Ảo Giác (hallucination) khi tương tác với Gen AI và cách khắc phục nó qua Prompt — phân tích 3 luận điểm về nguồn gốc của ảo giác và đưa ra các nguyên tắc viết prompt để giảm thiểu chúng. Trong khuôn khổ bài này, mình chỉ muốn để lại với bạn một nguyên tắc thực hành đơn giản:
Mọi thông tin, số liệu, tên người, URL, API method, package name — đều phải được kiểm chứng lại với nguồn đáng tin cậy. Không có ngoại lệ.
Điều đáng lưu ý nhất của hallucination không phải ở chuyện AI sai — mọi công cụ đều có lúc sai. Vấn đề là khi sai, AI không phát tín hiệu nào để bạn nhận ra. Một search engine sai sẽ trả ra kết quả lệch chủ đề — bạn nhận ra ngay. Một calculator sai sẽ cho số khác — bạn nghi ngờ. Còn LLM sai? Nghe vẫn rất giống lúc nó đúng.
Người dùng AI giỏi không phải người tin AI nhất, mà là người biết khi nào không nên tin.
RAG — Khi LLM cần “tra cứu” thay vì “nhớ”
Bạn đã từng nghe đến những app như “Chat với PDF”, “Hỏi đáp với knowledge base nội bộ công ty”, “Trợ lý tra cứu tài liệu pháp lý” chưa? Tất cả đều dựa trên một kỹ thuật chung là RAG — viết tắt của Retrieval-Augmented Generation. Cái tên nghe học thuật, nhưng ý tưởng cốt lõi rất gần gũi: thay vì bắt AI “nhớ” mọi thứ, ta cho phép nó “tra cứu” khi cần.
Vấn đề: LLM được train trên một tập dữ liệu cố định, đến một mốc thời gian cụ thể (knowledge cutoff — ngày cuối cùng AI được “học”). Nó không biết gì về:
- Codebase nội bộ công ty bạn.
- Tài liệu sản phẩm vừa update tuần trước.
- Cái PDF bạn vừa upload xong.
- Sự kiện diễn ra sau ngày knowledge cutoff.
Vậy làm sao các app kể trên lại trả lời được câu hỏi về nội dung mà LLM chưa từng được train? Câu trả lời là RAG.
Quy trình RAG có 2 giai đoạn rõ ràng:
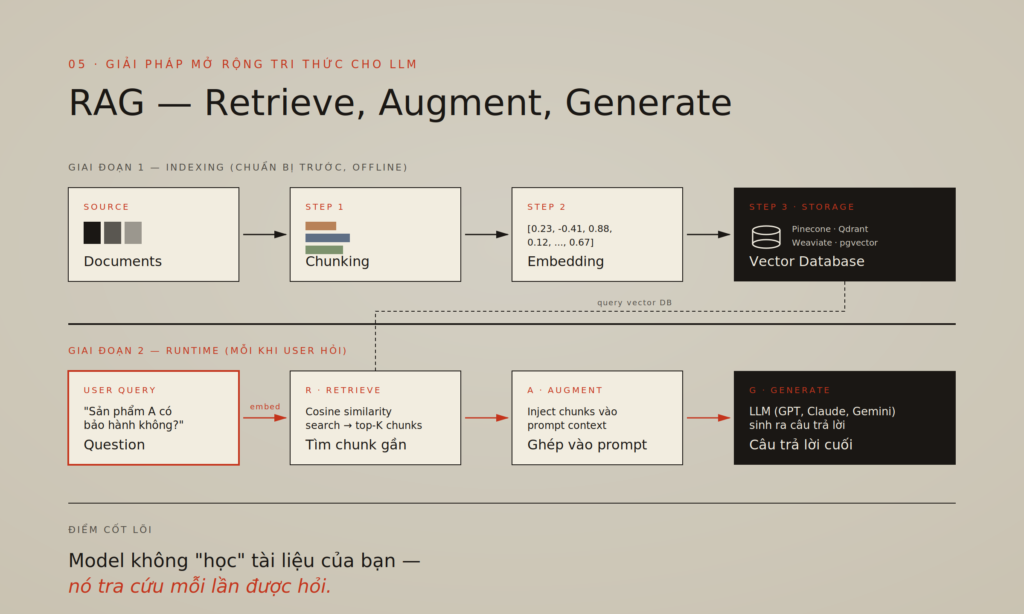
Sơ đồ quy trình RAG – một thuật ngữ AI quan trọng nhất hiện nay
Giai đoạn 1 — Indexing (chuẩn bị trước)
- Lấy tài liệu nguồn, chia thành các đoạn nhỏ — gọi là chunk. Có thể chia theo đoạn văn, theo câu, theo đề mục, tùy chiến lược.
- Đưa từng chunk qua một embedding model — như
text-embedding-3của OpenAI, hoặcbge,e5open source. Mỗi chunk trở thành một vector — một dãy số dài 1024 hoặc 1536 chiều, biểu diễn “ngữ nghĩa” của chunk đó. Hai chunk có ý nghĩa giống nhau sẽ có vector gần nhau trong không gian số. - Lưu các vector này vào vector database — loại database chuyên dụng cho việc tìm kiếm vector ở quy mô lớn: Pinecone, Weaviate, Qdrant, hoặc Postgres với extension pgvector.
Giai đoạn 2 — Retrieval & Generation (runtime, mỗi lần user hỏi)
- Lấy câu hỏi của user, chuyển nó thành vector bằng cùng embedding model.
- So sánh vector câu hỏi với toàn bộ vector trong database, dùng phép đo cosine similarity để lấy top-K chunk gần nhất (thường K = 3-10).
- Ghép các chunk này vào prompt cùng câu hỏi gốc, theo dạng: “Dựa trên thông tin sau: [chunks]. Hãy trả lời câu hỏi: [question]”.
- Gửi prompt mới cho LLM. LLM sinh ra câu trả lời.
Cốt lõi của RAG: Retrieve thông tin liên quan → Augment vào prompt → Generate câu trả lời. R-A-G.
Vì sao RAG là thuật ngữ AI quan trọng nhất 2 năm qua
Đây là kỹ thuật đứng sau gần như mọi sản phẩm AI hữu ích trong 2 năm qua. Cursor “biết” về codebase của bạn? RAG. NotebookLM trả lời từ PDF? RAG. Chatbot công ty trả lời chính xác về sản phẩm và quy định nội bộ? RAG.
Có một insight đáng để ý: khi sản phẩm AI “biết” tài liệu của bạn, nó không thực sự học được gì. Model vẫn là model gốc, không có thay đổi nào. Chỉ là phần context được bổ sung thêm thông tin liên quan từ vector database. Mỗi lần bạn hỏi, quá trình retrieval được thực hiện từ đầu — model không “nhớ” mà chỉ “tra cứu”. Hiểu được điều này, bạn sẽ nhìn các sản phẩm AI trên thị trường theo cách khác trước.
RAG hiện đại còn có nhiều biến thể nâng cao: hybrid search (kết hợp vector và keyword search), reranking (sắp xếp lại kết quả retrieval bằng model thứ hai), multi-hop retrieval (retrieve qua nhiều lượt), agentic RAG (agent tự quyết định khi nào cần retrieve). Nhưng dù phức tạp đến đâu, nguyên lý cốt lõi vẫn là R-A-G.
Vì sao 5 thuật ngữ AI này lại đáng học cùng nhau?
Bạn có thể tò mò: tại sao mình chọn đúng 5 cái này, mà không phải attention, transformer, fine-tuning, hay LoRA?
Lý do là chúng tạo thành một chuỗi nhân quả mà bạn gặp hằng ngày:
| Thuật ngữ | Khi hiểu, bạn giải quyết được |
|---|---|
| Token | Tối ưu prompt cho gọn nhẹ, dự đoán chi phí API |
| Context Window | Biết khi nào AI sẽ “quên”, thiết kế chiến lược chia task |
| Temperature | Chọn đúng setting cho từng loại nhiệm vụ |
| Hallucination | Biết khi nào nên tin, khi nào phải kiểm chứng |
| RAG | Hiểu cách các AI product hoạt động, biết khi nào nên build RAG |
Còn transformer, attention, fine-tuning — chúng cũng quan trọng, nhưng thuộc về cách model được xây dựng, không phải cách model được dùng hằng ngày.
Đặc biệt với developer, sau khi hiểu xong 5 thuật ngữ AI nền tảng này, bạn đã sẵn sàng cho các chủ đề chuyên sâu hơn như context engineering, prompt engineering, hoặc agent design. Trên Fx Studio có khá nhiều bài về hướng này — bạn có thể bắt đầu với Prompt Engineering trong 10 phút, rồi đến Multi-Layer Prompt Architecture khi muốn tìm hiểu về kiến trúc prompt phức tạp.
Tạm kết
Token là đơn vị. Context window là không gian. Temperature là núm điều chỉnh. Hallucination là cạm bẫy. RAG là giải pháp mở rộng. Năm mảnh ghép, ráp lại thành một bức tranh tương đối đầy đủ về cách LLM hoạt động trong thực tế.
Mình không nghĩ hiểu 5 thuật ngữ này sẽ biến bạn thành chuyên gia AI sau một đêm — nói vậy hơi cường điệu. Nhưng mình tin chắc một điều: hiểu được chúng, bạn sẽ dùng AI có chiến lược hơn — tối ưu prompt, kiểm soát output, biết khi nào nên kiểm chứng, biết khi nào cần đến RAG. Đó là khác biệt thật sự giữa người dùng AI và người làm việc cùng AI.
Nếu bạn mới bắt đầu, gợi ý của mình thế này: lần tới khi mở Claude hay ChatGPT, hãy thử ước lượng xem prompt của bạn khoảng bao nhiêu token, context đang chứa những gì, output có dấu hiệu hallucination nào không. Vài lần như vậy thôi, bạn sẽ hiểu sâu hơn hẳn so với việc đọc cả chục bài blog.
AI sẽ không đi đâu cả. Khoảng cách giữa những người dùng AI mơ hồ và những người dùng có hiểu biết sẽ ngày càng rộng trong vài năm tới. Mong bài này giúp bạn đứng về phía những người hiểu rõ công cụ mình đang dùng.
Cảm ơn bạn đã đọc đến đây. Hẹn gặp lại ở các bài viết sau trên Fx Studio.
Tài liệu tham khảo
Tokenization
Context Window
- Context Window Management for LLM Apps – Redis
- The Context Window Illusion: Why Your 128K Tokens Aren’t Working – DEV Community
Temperature & Sampling
Hallucination
RAG
- Learn How to Build Reliable RAG Applications in 2026 – DEV Community
- The Context Window Trap: Why 1M Tokens Won’t Save Your AI Agent – Rock Cyber Musings
Bài liên quan trên Fx Studio
- Vấn đề Ảo Giác (hallucination) khi tương tác với Gen AI và cách khắc phục nó qua Prompt
- Hướng Dẫn Kỹ Thuật Ngữ Cảnh WSCI & Cấu Trúc Workspace
- Prompt Engineering trong 10 phút
- Multi-Layer Prompt Architecture – Chìa khóa Xây dựng Hệ thống AI Phức tạp
- Thiết Kế AI_CONTEXT.md – Nghệ Thuật Giao Tiếp Với AI Qua Tài Liệu
- CO-STAR – Công thức vàng để viết Prompt hiệu quả cho LLM
Related Posts:
: Nâng Cao Độ Tin Cậy Của Mô Hình Ngôn Ngữ Lớn")



Leave a Reply
Donate – Buy me a coffee!


: Khung WSCI Áp Dụng Cho AntiGravity")
